Nested Fitting
Note
We use NFP (Nested Fitting Procedure) and HPO
(Hyperparameter Optimization) interchangeably to refer to this feature.
The main CLI entry point is tadah hpo. NFP is preferred in
prose to emphasise the two-level fitting structure that is specific to
Tadah!MLIP; HPO is the spelling used by every keyword and source-file
identifier.
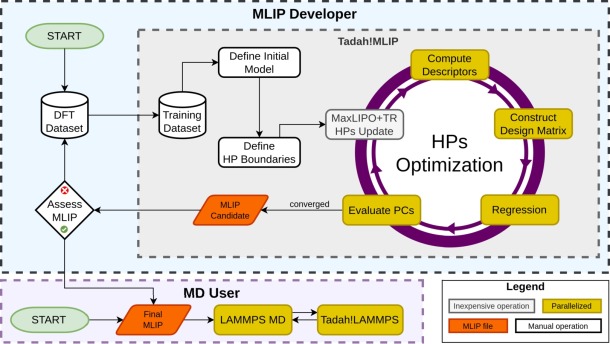
Workflow of the nested fitting procedure: the outer optimiser proposes new hyperparameters, the model is retrained, and each trial potential is validated against performance constraints that feed back into the global loss.
Nested fitting is Tadah!MLIP’s automated, two-level fitting workflow:
inner loop — ordinary regression that determines the learned parameters \(\mathbf w\) for a fixed model definition;
outer loop — a global optimiser that samples from the search space constraints (SSC), retrains the model, and judges the result against user-defined performance constraints (PC).
Letting a computer search the hyperparameter space helps to
escape the “good on the validation set, unstable in MD” trap;
trade accuracy for speed (or vice versa) in a reproducible way;
fold real-world performance constraints — elastic constants, phase stability, surface energies, … — directly into the loss function.
Background
A traditional MLIP workflow stops once regression converges on a training/validation split. Unfortunately, a potential that interpolates perfectly may still
disintegrate during an MD run,
produce an incorrect equation of state,
predict the wrong ground-state crystal,
extrapolate poorly beyond the training set.
Manual hyperparameter tuning or simply enlarging the training set are both tedious and not guaranteed to succeed.
Nested fitting tackles the problem by measuring emergent properties during the fit. Each trial potential is dropped into a short LAMMPS run; the resulting quantities are compared to their targets and the discrepancy contributes to a global loss
where \(w_i\) is the user-supplied weight, \(y_i\) the target, \(\hat y_i\) the prediction, and \(\mathcal L_i\) one of the built-in loss functions (L1, L2, Huber, Tukey, …).
The outer optimiser explores the hyperparameter space \(\Theta\)
declared with the OPTIM directive:
Because the model is retrained for every candidate \(\theta\), the procedure is computationally expensive but also powerful: it can expose regions of hyperparameter space that yield stable, accurate, and fast potentials. It is not a silver bullet — success still depends on sensible choices of performance constraints and search space limits.
Quick Start
Nested fitting needs up to three input files:
A training configuration — the same configuration file you would use for
tadah train. See Configuration File for the full key list.A validation file — a list of validation datasets passed via the
DBFILEkeyword. Optional: only required when the loss uses validation-set metrics (PC_ERMSE,PC_FRMSE, …); a run whose loss comes entirely fromPC_OBSERVABLE/PC_LAMMPSlines can omit--validation.An HPO configuration — the file documented on this page. Conventionally named
config.hpo.
The training configuration’s DBFILE is itself optional when every
model weight is pinned via FIXINDEX/FIXWEIGHT (see
Pinning and searching linear coefficients) — with no free weights there is nothing for the
least-squares stage to fit. In that mode the element set must be
declared explicitly with the ATOM key, at least one loss source must
remain, and the run is serial-only (MPI builds reject it).
The driving command line is
tadah hpo --config <config.train> --hpotarget <config.hpo> --validation <config.val>
A minimal config.hpo:
OPTIMIZER
STRATEGY
TYPE PLAIN
LIB DLIB
ALGO BFGS
MAXEVAL 50
ENDSTRATEGY
ENDOPTIMIZER
LOSS L2
PC_ERMSE 0 1.0
OPTIM RCUT2B (1) 4.0 6.0
See Example 2 - Basics: Nested Fitting Procedure for a slightly bigger walkthrough, and Nested Fitting — Worked Examples for a graded series of fifteen worked examples.
Configuration file
This section is the reference for the HPO configuration file. For an even terser keyword reference — every flag, every default, plus the OPTIM-able context keys table — see the in-tree HPO/README.md.
Block hierarchy
The HPO configuration is a sequence of root-level keywords (LOSS,
OPTIM, PC_*, OUTPUT, …) plus a single OPTIMIZER
ENDOPTIMIZER block. The optimiser block has nested blocks, listed
in the order they normally appear:
OPTIMIZER
INIT ... ENDINIT # optional: seeding strategy chain
NOISE ... ENDNOISE # optional: objective-noise calibration
STRATEGY ... ENDSTRATEGY # required: TYPE + driver + decorators
EXPLORE ... ENDEXPLORE # required for TYPE PRESTAGE
REFINE ... ENDREFINE # required for TYPE PRESTAGE
INNER ... ENDINNER # optional: NLopt MLSL/AUGLAG inner
RESTART ... ENDRESTART # optional decorator
ENDOPTIMIZER
Block keywords are case-sensitive. Comments start with #; long
lines may be continued with a trailing \.
A legacy form without a STRATEGY block — LIB/ALGO/MAXEVAL
written directly inside OPTIMIZER — is still accepted and behaves
exactly like STRATEGY { TYPE PLAIN ... }. It is fine for short
single-shot runs but cannot express MULTISTART, PRESTAGE,
init chains, or RESTART decorators; those features
require the explicit grammar.
LOSS — global loss function
LOSS <Name> [<extra params>]
The default loss applied to every metric that does not override it.
PC_LAMMPS per-variable lines may pick a different loss locally.
Name |
Extra params |
Comment |
|---|---|---|
|
— |
\(|x|\) |
|
— |
\(x^2\) |
|
|
quadratically near zero, linear beyond δ |
|
|
redescending, zero influence for |
|
— |
smooth alternative to L1 |
|
— |
log-scaled L2 (non-negative targets) |
Root-level loss control:
Key (type) |
Description |
|---|---|
|
Cap on total loss; values above are clipped (default: max
double). May be overridden per-script with |
OPTIM — search space constraints
The OPTIM directive declares which configuration keys the outer
optimiser may vary, and over what bounds:
OPTIM <KEY> (indices) <low> <high>
<KEY>— any optimisable key from the training configuration. For the full list of OPTIM-safe keys (and the tightly enumerated set of unsafe ones, e.g.RCUT2BwithD2_EAM), see the OPTIM-able context keys: reinit-safety reference table in HPO/README.md.(indices)— selects a subset of the values bound to<KEY>. Indices follow the order in the training configuration and start from 1. Comma-separated lists, rangesa-b, and stridesa-b:sare all accepted (e.g.(1,4,7-10:2)).<low>,<high>— floating-point bounds.highmust be strictly greater thanlow.
OPTIM lines may be repeated for the same key with different indices.
Two weight-related special cases:
OPTIM FIXWEIGHT— the(indices)name model weights (the weightsFIXINDEXpins), not positions in theFIXWEIGHTvalue list.OPTIM FIXWEIGHT (5) -1 1searches model weight 5 and it is an error if 5 is not listed inFIXINDEX. See Pinning and searching linear coefficients.OPTIM WEIGHTS— rejected. The linearWEIGHTSare re-fitted by least squares on every evaluation, so optimising them directly would be a silent no-op; pin them withFIXINDEX/FIXWEIGHTinstead.
Cutoffs of knot-family refit potentials
For potentials written by tadah refit with the knot basis families
(D2_Knot5 two-body, DM_REAM knot density), the effective cutoff
is the largest knot position: each knot function \((t-r)_+^k\)
vanishes smoothly at its own knot, so RCUT2B/RCUTMB are derived
quantities (see Cutoffs: knot channels are derived, blip channels are fixed). tadah hpo enforces this
automatically:
at startup, a stated
RCUTthat differs from the largest knot is corrected (with a warning) before anything is built;on every evaluation, the
RCUTkeys are re-derived from the current (possiblyOPTIM’d) knot positions, so searchingOPTIM CGRID2B/CGRIDMBmoves the effective cutoff with the knots;the neighbour list is sized once for the largest cutoff the search can reach — including the upper bounds of any
OPTIMblock on the knot grids — so no evaluation can silently outrun it.
Consequently OPTIM RCUT2B / OPTIM RCUTMB on a knot-family
potential is a wasted search dimension (the value is overridden each
evaluation; a startup warning says so). To search the effective cutoff,
put an OPTIM block on the knot positions instead — e.g. uncomment the
OPTIM CGRID2B line of the outermost knot in the refit-generated
hpotarget and widen its upper bound.
Blip-family potentials are unaffected: their hard truncation at the
stated RCUT is part of the fitted model, so the key remains
authoritative (warnings fire if OPTIM bounds let a blip’s support
cross it).
Pinning and searching linear coefficients
By default the model’s linear WEIGHTS are re-fitted by least squares
inside every objective evaluation, while OPTIM searches the
nonlinear hyperparameters. FIXINDEX/FIXWEIGHT in the training
configuration carve weights out of that LS fit: pinned columns are
removed from the design matrix, their contribution is subtracted from
the target, and the remaining weights are fitted against the residual.
The i-th FIXWEIGHT value pins the weight named by the i-th
FIXINDEX entry; a lone key is an error, and NORM true is
incompatible with pinning (the values would live in normalized feature
space).
Mixed mode — LS-fit most weights, hold one, search another. With a 5-weight model: weights 1–3 LS-fitted, weight 4 held at 0.75, weight 5 searched by the optimiser:
# training configuration (config.train)
DBFILE train.tadahdb
FIXINDEX 4 5
FIXWEIGHT 0.75 1.20 # 0.75 pins w4; 1.20 seeds w5
# config.hpo
OPTIM FIXWEIGHT (5) -2.0 2.0 # (5) = model weight 5
All-fixed polish — the tadah refit workload. FIXINDEX covers
every weight, so the LS solve is vacuous and skipped (including the
per-evaluation design-matrix build); the optimiser searches the
coefficients directly:
FIXINDEX 1-28
FIXWEIGHT <28 fitted values>
# config.hpo: one OPTIM FIXWEIGHT (i) line per coefficient
# (this is exactly what `tadah refit` emits as refit.hpotarget)
No training data — with every weight pinned, the training DBFILE
may be omitted entirely. Declare the element set with ATOM and keep
at least one loss source (--validation metrics, PC_OBSERVABLE,
or PC_LAMMPS):
# config.train: a fitted potential, no DBFILE line
ATOM Ta
FIXINDEX 1-28
FIXWEIGHT <28 values>
# config.hpo
PC_LAMMPS --script Ecoh.in --hotvar hot_a0 2.5 4.5 3.302 --varloss Ecoh 8.10 800
OPTIM FIXWEIGHT (1-28) ...
# command line: --validation may be omitted
tadah hpo -c config.train --hpotarget config.hpo
This mode is serial-only (MPI builds reject it — there is no design
matrix to distribute). Misconfigurations (lone keys, size mismatches,
out-of-range indices, missing loss sources, incomplete pin coverage
without a DBFILE) are rejected at startup with actionable messages.
With FIXINDEX present, analytical/HYBRID gradient strategies fall
back to finite differences for all parameters: the analytical chain
assumes the unconstrained LS solution map, which pinning invalidates.
Derivative-free algorithms (e.g. NLOPT LN_BOBYQA) are a natural
choice for coefficient searches.
PC_* — performance constraints
Energy / force / stress validation metrics
Validation-set metrics are evaluated on every DBFILE listed in the
--validation file. Each line takes a target value and a weight:
PC_<METRIC> <target> <weight>
Key |
Quantity |
|---|---|
|
Energy mean absolute error (per atom) |
|
Energy root-mean-square error (per atom) |
|
Energy relative RMSE |
|
Coefficient of determination (R²) for energies |
|
Force component RMSE |
|
Stress component RMSE |
These constraints use the global LOSS selected above.
Physics-informed constraints (PC_LAMMPS)
PC_LAMMPS runs a regular LAMMPS script against each trial potential
and feeds one or more LAMMPS equal-style variables back into the
loss:
PC_LAMMPS --script in.mysim \
--varloss myVar 0 100 \
--varloss myOtherVar 145 10
A long PC_LAMMPS line may be split with a trailing back-slash
(\). Tadah!MLIP creates an isolated LAMMPS_NS::LAMMPS instance
per script per worker thread; instances are reused across iterations
(the script’s own clear directive resets simulation state between
runs, so existing scripts work unmodified).
Required options
--script <file>LAMMPS input file containing the variable definitions.
--varloss <name> <target> <weight> [loss-type p₁ p₂ …]The variable
<name>(defined inside the LAMMPS script) is read at the end of the run and combined with<target>and<weight>via the globalLOSS(or the per-line override). Optional trailing tokens override the loss for this variable only.
Additional options
--invar <name> <value>Inject a variable (equivalent to LAMMPS’
-varflag), letting the same script be reused for several structures or pressures.--outvar <name>Record the variable in
outvar.tadahwithout contributing to the loss. Useful for diagnostic plots.--failscore <value>Override the global
FAILSCOREfor this script. If LAMMPS crashes or the loss exceeds this value the optimiser receivesFAILSCOREfor the whole iteration.--ncpu <m>Request m MPI ranks for this script in MPI builds. In the default serial build the option is parsed and accepted but does not change runtime; HPO logs a stderr warning when
--ncpu > 1is set in a non-MPI build. See Performance & parallelism.--hotvar <name> <min> <max> [<initial>]Declare this
PC_LAMMPSline as hot: a two-phase evaluator for parameters that other scripts depend on. Hot scripts run alone in phase A of each iteration (in parallel with other hot scripts), exposevariable <name> string …from the LAMMPS script (see Warm-start protocol and bad-potential early-exit for the requiredstring-style readback), and the returned value is validated against[min, max]. Validated values are cached per(script, name)and propagated as${<name>}strings into every cold (no---hotvar)PC_LAMMPSscript in phase B.<initial>is optional; when omitted the midpoint of[<min>, <max>]seeds the first iteration. If a hot value lands outside[min, max]HPO fail-scores the iteration and skips phase B (a graded failure whenFAILSCORE_GRADING ON— see Failure handling — graded FAILSCORE).--failvar <name> [<scale>]Declare a violation variable: a nonnegative LAMMPS
equal-style variable that is0when the simulation vouches for itself and> 0when it failed, with the magnitude measuring how badly (natural units;<scale>converts to the dimensionless failure measure, default 1). When it reads> 0the sim is treated as failed, its outvars are excluded from the fit, and — withFAILSCORE_GRADING ON—scale × valuegrades the failure loss so the optimiser is pulled toward feasibility instead of hitting a constant. Define it early in the script (right after the risky command), so it is still readable when a later section times out. Like--varloss/--outvarnames, the variable must be defined in the script as anequal-style variable — a typo’d name is a startup error, not a silently-disabled check. Replaces the old “sentinel value” idiom (returning-1000as fake data). See Failure handling — graded FAILSCORE.
Per-metric bad-pot pre-filter
PC_<METRIC> --skip-above <cap> and PC_<METRIC> --skip-rel <ratio>
attach a per-metric pre-filter on the dataset error counters
(PC_EMAE, PC_ERMSE, PC_ErRMSE, PC_ERSQ, PC_FRMSE,
PC_SRMSE). Both gates fire before any PC_LAMMPS work for
the iteration:
--skip-above <cap>fail-scores the iteration when the metric exceeds the absolute<cap>.--skip-rel <ratio>fail-scores whenmetric > ratio × running_bestfor that same metric.
Both filters can be applied to the same metric line. They short-cut obviously bad potentials so wall-time is not spent on LAMMPS phases that would never compete.
Result contract for user scripts
LAMMPS scripts driven by HPO must communicate their results back
only through --varloss / --outvar (LAMMPS equal-style
variables). They should avoid writing files (dumps, restarts,
write_data, custom logs) unless filenames are made unique, because
all OpenMP threads share the process working directory.
If -log <file> or -screen <file> is supplied explicitly inside
a PC_LAMMPS entry, HPO appends .t<thread_id> per OpenMP thread
(so e.g. -log run.log becomes run.log.t0, run.log.t1, …).
-log none and -screen none are left untouched.
Failure handling — graded FAILSCORE
What problem this solves
When a candidate potential makes a simulation fail — a relaxation that
does not converge, a hot value outside its window, a hung run that had
to be killed — the iteration traditionally returns the constant
FAILSCORE. A constant is a flat landscape: inside a failing
region every proposal looks equally bad, so annealers random-walk or
freeze (their step-size adaptation has two absorbing states on a flat
or cliff-edged landscape), parallel-tempering ladders die on the
plateau, and gradient methods see exactly zero slope. The optimiser
receives no hint of which way is out.
FAILSCORE_GRADING ON replaces the constant with a graded value:
every failed iteration returns a loss inside the reserved band
[0.999 × FAILSCORE, FAILSCORE) that decreases as the candidate
gets closer to working. Feasible results always win (they are orders
of magnitude below the band), every internal failure filter still
recognises the value as a failure, and within the failing region the
optimiser can finally descend toward feasibility.
The knobs, most important first
FAILSCORE <value>(root)The failure ceiling, as before — but with grading ON it must be a finite positive number (e.g.
1e9); the legacyDBL_MAXdefault is rejected at startup. Choose it a few orders of magnitude above your worst plausible real loss.FAILSCORE_GRADING ON|OFF(root, defaultOFF)The master switch.
OFFis byte-identical to the legacy behaviour. Everything below only matters when this isON. Environment override:TADAH_FAILSCORE_GRADING=ON|OFF.--failvar <name> [<scale>](perPC_LAMMPSline)The per-script violation channel (see the option reference above and the examples below). Costs one
variableline per script and upgrades that script’s failures from “counted” to “measured”.PC_FAILPROBE --script <f> --outvar <S> [--gate <T>] [--s0 <v0>](root)A tiny, minimiser-free sanity probe executed at the front of every iteration’s parallel batch. Its first
--outvaris a single nonnegative scalarSmeasuring how unphysical the candidate is (0 = sane).Sbecomes the failure measure for the failure modes that cannot measure themselves — hung runs that were killed, crashed potential builds — and, optionally, a gate: whenS > <T>the iteration is short-circuited before wasting the full simulation budget.<v0>sets the saturation scale of the grading curve forS(default 1; a good choice is the seed potential’sStimes a small factor). At most one probe line is allowed;--varlosson it is rejected (the probe grades failures — it must not shape the feasible objective).--gate <T>(onPC_FAILPROBE)The only knob that needs real care. If the gate can fire on a candidate that would actually have succeeded, you have changed the objective, not just saved time. Calibrate it from a short run: journal the
Sstatistics of accepted iterations, then setTfar above anything a feasible candidate produces (same philosophy as the--skip-abovecaps). Gate firings are journaled and rate-limited; watch the counter.PC_WORKER_TIMEOUT/ per-sim--maxtime(existing)Unchanged, but they interact: a killed hung run is graded by
S(band C below), so with a probe defined even timeouts become directional instead of flat.
Order of firing within one iteration
train/validate → [skip caps? → graded band D, stop]
dispatch batch: FAILPROBE first (cheapest → returns first),
hot scripts + independent cold scripts alongside
├─ probe returns S
│ ├─ S ≤ gate (or no gate): S is stored for later grading
│ └─ S > gate: iteration short-circuited → band D graded by S;
│ queued sims are cancelled; in PROCESS mode this
│ iteration's in-flight sims are killed (other concurrent
│ iterations on the shared pool are never touched)
├─ each sim finishes → failvars read (0 ⇒ OK; >0 ⇒ band B, graded)
│ hot values validated → out of window ⇒ band A, graded by the
│ normalized distance to [min, max]
├─ a sim times out in-script (timer timeout) → instance still
│ alive → failvars still readable → band B
└─ a sim hangs → parent deadline kill (PROCESS mode) → nothing
readable → band C, graded by S
dependent cold wave → loss assembly:
no failure → normal loss (identical to grading OFF)
any failure → L_fail in [0.999·FS, FS), see the band table
The severity bands (worst on top) encode the natural repair path — make the potential sane, then runs complete, then outputs valid, then windows satisfied, then feasible:
Band |
Failure modes |
Graded by |
|---|---|---|
D |
probe gate fired; potential build crashed; skip caps |
|
C |
run hung and was killed; worker died |
|
B |
run completed but failed: in-script timeout, |
failvar sum + failed fraction |
A |
hot value outside its window |
normalized distance to the window |
Cross-band ordering is fixed (every A value beats every B
value, etc.), within a band less violation is strictly better, and one
iteration gets exactly one band (the worst one that occurred).
Failures that are not the potential’s fault — a LAMMPS instance that
could not be created, worker crash-loops — are deliberately not
graded (a directionless constant), so the optimiser never chases
infrastructure noise.
Designing failprobe.in
Four rules make a good probe:
It must not be able to fail or hang. Single-point evaluations only: fixed cells,
run 0— nominimize, nobox/relax, no dynamics.It must be smooth in the potential parameters. Build
Sfrom hinge/softplus penalties of energies, forces and stresses — these are smooth functions of the parameters, soSgives a descent direction.It must be cheap — a few small single-point cells cost milliseconds and disappear into the parallel batch.
No ``label``/``jump`` loops. Scripts are executed command-by-command through the LAMMPS library interface, where the file-rewind machinery behind
jumpdoes not work reliably (it can half-work in ways that depend on leftover loop variables from the previous evaluation in the cached instance). Unroll the few cells you probe — it is also easier to read.
Good ingredients (all already proven in the pen_* observables):
equation-of-state sanity (energy at a handful of fixed volumes around
equilibrium: hinge on non-monotonic compression branches), near-zero
forces on the ideal lattice, finite and positive stress response. A
ready-to-adapt example:
# failprobe.in — minimiser-free sanity scalar S for bcc metal.
# Contract: NEVER minimize/box-relax/run>0; define S even on the
# weirdest potential; keep it O(ms); no label/jump loops (rule 4) —
# the three volumes are unrolled. `variable X equal $( ... )`
# captures the value IMMEDIATELY, and equal-style redefinition
# replaces the old value, so the captures stay fresh in the cached
# instance on every evaluation.
# -- E(V) monotonicity: 2-atom bcc cells at 0.90/1.00/1.10 a0 -----
# (a0 = 3.30 reference lattice constant, baked into the lattice
# commands below)
clear # scripts run in a CACHED LAMMPS instance:
# always start with clear (variables survive)
units metal
dimension 3
boundary p p p
atom_style atomic
atom_modify map array
lattice bcc $(3.30*0.90)
region box block 0 1 0 1 0 1
create_box 1 box
create_atoms 1 region box
mass 1 180.95
pair_style tadah
pair_coeff * * EXTERN Ta
run 0 post no
variable e_m10 equal $(pe/atoms) # captured now (immediate $)
clear
units metal
boundary p p p
atom_style atomic
atom_modify map array
lattice bcc 3.30
region box block 0 1 0 1 0 1
create_box 1 box
create_atoms 1 region box
mass 1 180.95
pair_style tadah
pair_coeff * * EXTERN Ta
run 0 post no
variable e_0 equal $(pe/atoms)
clear
units metal
boundary p p p
atom_style atomic
atom_modify map array
lattice bcc $(3.30*1.10)
region box block 0 1 0 1 0 1
create_box 1 box
create_atoms 1 region box
mass 1 180.95
pair_style tadah
pair_coeff * * EXTERN Ta
run 0 post no
variable e_p10 equal $(pe/atoms)
# compressed branch must rise toward small volume; expanded branch
# must rise toward large volume (bound state). Hinge each violation.
variable h_comp equal $(ternary(v_e_m10<v_e_0, v_e_0-v_e_m10, 0.0))
variable h_exp equal $(ternary(v_e_p10<v_e_0, v_e_0-v_e_p10, 0.0))
# -- force sanity: rattle a cell DETERMINISTICALLY (fixed seed) and
# hinge on absurd forces. Do NOT probe fmax on the ideal lattice --
# there it is zero by symmetry for ANY potential, sick or sane.
clear
units metal
boundary p p p
atom_style atomic
atom_modify map array
lattice bcc 3.30
region box block 0 2 0 2 0 2
create_box 1 box
create_atoms 1 region box
mass 1 180.95
pair_style tadah
pair_coeff * * EXTERN Ta
displace_atoms all random 0.05 0.05 0.05 12345 units box
run 0 post no
variable h_frc equal $(ternary(fmax>20.0, fmax-20.0, 0.0))
# -- compose S: bounded, nonnegative, 0 for a sane potential ------
variable S equal $(v_h_comp + v_h_exp + v_h_frc)
with the configuration line
FAILSCORE_GRADING ON
PC_FAILPROBE --script pc_lammps/failprobe.in --outvar S --s0 0.5
# add "--gate 50" ONLY after calibrating S statistics on your seed
(Adapt the element, a0, volumes and thresholds to your system; add
Born-stability hinges via finite-difference stress probes on fixed
strained cells if shear stability matters for your fits — the
pen_born machinery in the examples shows the pattern.)
--failvar recipes for typical scripts
Pressure-target relaxation (box/relax at pressure P): the
convergence check already computes the violation — export it:
fix relax all box/relax iso ${P_bar} vmax 0.003
minimize 1e-10 1e-10 2000 20000
unfix relax
variable Pres equal $(press)*1.0e-4
# 0 when converged within 1 GPa; the residual (GPa) otherwise:
variable fail_press equal $(ternary(abs(v_Pres-v_P_GPa)<1.0, 0.0, abs(v_Pres-v_P_GPa)))
# ... only now compute the real observables ...
PC_LAMMPS --script pc_lammps/elastic_P_single.in --invar P 300 \
--varloss Cp_P300 232.8 7.6 --varloss C44_P300 332.9 3.9 \
--failvar fail_press 0.01
Minimisation that must actually converge (vacancy, surface, stacking-fault energies): grade by the residual force instead of returning a sentinel:
minimize 1e-10 1e-10 2000 20000
# 0 when converged; the residual max force (eV/Å) otherwise:
variable fail_fmax equal $(ternary(fmax<1.0e-8, 0.0, fmax))
PC_LAMMPS --script pc_lammps/vac_bcc_P_fast.in ... --failvar fail_fmax 10
Both patterns follow the same contract: define the failvar
immediately after the risky command (it survives a later in-script
timeout), keep it 0 on success, and make its magnitude the natural
physical distance from success. Where your scripts currently return
sentinel values (-1000) as fake observables, move that logic into a
--failvar — the sentinel stops polluting the fitted region and its
information starts steering the optimiser instead.
Setup effort, honestly
Level 0 (just FAILSCORE_GRADING ON): hot-window rejections and
partial failures become graded automatically — no script changes, and
the worst optimiser pathologies (plateau death, step-size collapse)
disappear. Level 1 (one --failvar line per script that has a
convergence check): minutes per script. Level 2 (the probe): one
script, once, assembled from the same hinge idioms as the pen_*
observables. The only knob that can change your objective if set
carelessly is the probe --gate — leave it off until you have
calibrated S.
OPTIMIZER block — common attributes
The driver-attribute keys below are accepted wherever an
OptimizerSpec is the active receiver: at the top level of
STRATEGY (when TYPE is PLAIN or MULTISTART) and inside
EXPLORE, REFINE, and INNER sub-blocks.
Key (type) |
Description |
|---|---|
|
Optimisation library: |
|
Algorithm (see table below). |
|
Maximum number of evaluations. |
|
Maximum wall-time in seconds (also accepted at root level). |
|
Stop when the loss falls below this value. |
|
Relative tolerance on the loss. |
|
Absolute tolerance on the loss. |
|
Relative tolerance on hyperparameters. |
|
Absolute tolerance on hyperparameters. |
|
Population size for population-based algorithms. |
|
Initial step size. |
|
Random seed (default: current time). Inside an |
|
Storage size required by some NLOpt algorithms. |
|
Outer thread count for |
|
Generic key/value passed to the algorithm (e.g.
|
LIB |
ALGO (algorithms from the selected library) |
|---|---|
|
|
|
All gradient-free NLOpt globals ( Note Analytical loss gradients are work in progress and are
not enabled in this beta release. Every gradient-using
algorithm ( |
|
|
|
|
CERES PARAM keys
The four CERES algorithms accept these algorithm-specific PARAM
entries (all keys are optional unless noted):
Key |
Effect |
|---|---|
|
Relative finite-difference step for the numerical gradient (default |
|
Numeric-diff method: |
|
Gradient-infinity-norm convergence tolerance (Ceres |
|
Override on Ceres’ |
|
Maximum line-search step-size iterations. |
|
(LBFGS only) limited-memory rank, default |
|
(NLCG only) variant: |
The MAXEVAL cap is enforced at the host-evaluation level by an
external counter shared with the GradientProvider. Ceres’
internal iteration counting is intentionally given a high sentinel so
that one Ceres iteration’s worth of finite-diff samples (2 × N under
CENTRAL) is correctly accounted for against the user budget.
The DLIB:BFGS path also routes its gradient through the same seam.
PARAM fd_step keeps its existing semantics; the chief observable
change is that gradient evaluations now count toward MAXEVAL via
the same shared counter (previously dlib’s internal central-diff
samples bypassed the cap by 2 × N per iteration).
INIT block — seeding strategies
Outside an INIT { ... } ENDINIT block the optimiser starts at the
single point taken from the values next to your OPTIM lines (the
implicit CONFIG seed). Inside an INIT block you may declare a
chain of strategies that produces multiple starting points.
Chain entries
Each STRATEGY <method> line appends one entry to the chain.
The chain is resolved into a flat list of starting points before the
optimiser runs.
Method |
Args |
Default K |
Effect |
|---|---|---|---|
|
(none) |
1 |
Take the value next to each |
|
|
|
|
|
|
|
Latin-hypercube sample (one per stratum per dim). |
|
|
|
Sobol low-discrepancy sequence. |
|
path |
1 |
Read a previous |
Top-level keys inside the INIT block
Key |
Type |
Default |
Effect |
|---|---|---|---|
|
repeatable |
single |
Append a strategy entry to the chain (see table above). |
|
uint |
sum of strategies’ default K |
Cap on total starting points produced. |
|
uint |
random |
Seed for stochastic strategies (RANDOM / LHS / SOBOL). |
|
|
|
What to do when |
There is no INCLUDE_CONFIG keyword. The in-config point is part of
the chain only when STRATEGY CONFIG is listed explicitly; an
INIT block with no STRATEGY line (or no INIT block at all)
resolves to a single CONFIG point. The removed INCLUDE_CONFIG
and INIT_INCLUDE_CONFIG keywords are rejected with a message
pointing at STRATEGY CONFIG.
Two implementation details affect reproducibility:
The chain is resolved in the exact order it is written — no entry is reordered. To make the warm point iter 0, list
STRATEGY WARMfirst in theINITblock.When the writer that produced the
WARMfile dumped# HOT_A0 <script> <a0>lines,WARMreads them and primes the warm-start cache (see Warm-start protocol and bad-potential early-exit).
How many seeds does the optimiser actually consume?
A chain that produces more starting points than the optimiser can use emits a stderr warning at config time and silently discards the rest.
Optimiser |
Seeds consumed |
|---|---|
|
All K (forwarded as |
|
First only ( |
Any |
First only. |
|
First only — used as eval 0, then sweep. |
|
First only — used as the SA chain’s starting state after T0 calibration. |
|
First only — the seed replica/walker starts there; the rest jitter around it ( |
MULTISTART > 1 runs the inner optimiser K times and consumes one
seed per start. DLIB:GFS collapses to a single inner call because
GFS already takes K seeds natively.
Bound transforms
Search-space dimensions whose high/low ratio exceeds LOG_HP
(declared inside STRATEGY or OPTIMIZER) are log-transformed.
All internal arithmetic happens in transformed space; only the
reported parameter values are exponentiated back. Default is no
transform — set LOG_HP <ratio> to opt in.
STRATEGY block
The STRATEGY { ... } ENDSTRATEGY block is the run-policy hub. Its
TYPE selects the dispatch shape:
|
Effect |
|---|---|
|
Single-shot run of the driver named by |
|
Run the driver |
|
Two-stage: an |
TYPE PLAIN
The simplest dispatch: a single run of LIB/ALGO. The driver
attribute table above lists every accepted key. No nested blocks
other than RESTART and INNER (for NLopt MLSL/AUGLAG) are
relevant.
TYPE MULTISTART
Runs the inner driver N_STARTS independent times. The host’s
best-tracker keeps the global minimum across all runs.
Key |
Args |
Default |
Effect |
|---|---|---|---|
|
int ≥ 1 |
|
Number of independent starts. |
|
int ≥ 1 |
|
Concurrent starts (currently parsed and validated; runs
sequentially with a stderr warning if |
|
int ≥ 1 |
derived |
Per-start |
MULTISTART with N_STARTS > 1 is rejected at validate-time for
NLOPT:GN_* algorithms (those globals consume only one starting
point). Local optimisers — NLOPT:LN_* (gradient-free) and
NLOPT:LD_* (gradient via the shared finite-difference seam) — and
DLIB:GFS / DLIB:BFGS all accept multistart.
TYPE PRESTAGE — staged global → local
A self-contained EXPLORE { ... } ENDEXPLORE sub-block describes the
first (exploration) phase; the outer LIB/ALGO drives the
second (refinement) phase over the top-K candidates harvested by the
EXPLORE pass.
STRATEGY
TYPE PRESTAGE
LIB DLIB
ALGO BFGS # local refinement, runs SECOND
MAXEVAL 60
TOPK 3
EXPLORE
LIB DLIB
ALGO GFS # global exploration, runs FIRST
MAXEVAL 200
ENDEXPLORE
ENDSTRATEGY
Key |
Args |
Effect |
|---|---|---|
|
int ≥ 1 |
Number of best (loss, params) pairs the EXPLORE phase
forwards to refinement. |
The EXPLORE block accepts the full driver-attribute set
(LIB/ALGO/MAXEVAL / …); it inherits the outer bounds and
log-transform automatically.
LIB TADAH ALGO ANNEAL — classic Simulated Annealing
The in-tree TADAH library exposes a classic Kirkpatrick/Metropolis
Simulated Annealing driver as ALGO ANNEAL. It is a single-shot
optimiser: select it from a STRATEGY { TYPE PLAIN } block, or wrap
it in MULTISTART for multiple independent chains.
References:
Kirkpatrick, S., Gelatt, C. D., and Vecchi, M. P. Optimization by simulated annealing. Science 220 (4598), 671–680, 1983.
Metropolis, N., Rosenbluth, A., Rosenbluth, M., Teller, A., and Teller, E. Equation of State Calculations by Fast Computing Machines. J. Chem. Phys. 21, 1087–1092, 1953.
The algorithm operates in transformed (post-LOG_HP) parameter
space: every Metropolis trial draws x' = x + sigma * N(0, I),
mirror-reflects out-of-bounds components back into the box, and
applies the Metropolis acceptance Δf <= 0 or
rand < exp(-Δf / T). Temperature cools geometrically:
T <- T * RT.
When PARAM T_HOT is not set, the driver auto-calibrates T0
from the seed point’s neighbourhood: the seed is evaluated first,
then T0_PROBES sigma-scaled Gaussian perturbations of it are
probed (drawn from a dedicated RNG stream, so probing never shifts
the proposal sequence), and
T0 = median(uphill finite Δf) / ln(1/P), where P =
PARAM T0_PACCEPT is the target early acceptance probability.
Probes that score FAILSCORE are excluded from the statistics —
on realistic cliff landscapes a naive whole-box estimator either
never sees the basin (T0 arbitrarily cold) or mixes the cliffs
in (T0 ~ FAILSCORE, a never-cooling random walk). If the seed
itself scores FAILSCORE, one batch of uniform box probes is
spent to re-anchor the chain on the best finite point found; if
nothing finite turns up the run aborts with a hard error listing the
remedies (set PARAM T_HOT, provide a viable starting point, or
shrink the OPTIM boxes).
Knobs are passed via the existing PARAM <key> <value> grammar
inside the STRATEGY block. Defaults are listed below.
PARAM |
Default |
Effect |
|---|---|---|
|
auto |
Starting/hottest temperature (renamed from |
|
auto |
Cooling floor; the schedule ends when |
|
|
Geometric cooling factor in |
|
|
Markov-chain length per temperature (CLASSIC only; ignored and
unvalidated under |
|
|
Per-dim sigma as a fraction of |
|
|
Local probes around the seed used to calibrate T0. |
|
|
Target acceptance probability for T0. Deliberately LOW: on
FAILSCORE-cliff landscapes the uphill-dE distribution is
heavy-tailed, and classic targets (0.8) yield a T0 so hot the
schedule never cools within realistic budgets. Benchmarked on
a 42-D EAM workload: 0.05 beat 0.10/0.20/0.80 and a hand-tuned
|
|
|
Plateau window in rungs for the |
|
|
When a schedule cools out ( |
|
|
Start-temperature factor for each successive re-anneal, in
|
Top-level STEP <s> overrides PARAM STEP_FRAC with a uniform
sigma applied to every dimension; the entry banner echoes which is in
use. SEED <int> seeds the RNG.
Stops honoured: MAXEVAL (hard cap on host calls — including T0
probes), MAXTIME, STOPVAL, the T_MIN floor (subject to
REANNEAL), and — when FTOL_REL and/or FTOL_ABS is set —
the Corana sec.-4 eps-NEPS plateau rule: the run stops once the
end-of-rung current value stays within
eps = max(FTOL_ABS, FTOL_REL * |f|) of the previous NEPS
end-of-rung values and within eps of the running best. (The
rule deliberately does not watch the monotone best-so-far: a chain
still exploring at high T must not be stopped just because the best
stalled.)
When the finite T0 probes show zero loss variation (a constant
landscape at probe scale), or every local probe around a finite seed
hits FAILSCORE, HPO falls back to T0 = 1.0 and emits a
WARNING line; set PARAM T_HOT or adjust STEP_FRAC in that
case.
Knobs that are dead for this driver are hard errors, not silent
no-ops: XTOL_REL/XTOL_ABS, VECTOR_ARR, GRAD_STRATEGY,
unknown PARAM keys (typo guard), and THREADS/POPULATION
(which belong to the parallel drivers TADAH:ANNEAL_PT /
TADAH:ANNEAL_PA).
Corana adaptive variant (opt-in)
Setting PARAM CORANA 1 switches the inner loop from classic
Kirkpatrick/Metropolis to the Corana adaptive scheme (refs:
Corana, Marchesi, Martini, Ridella, ACM Trans. Math. Soft. 13:262,
1987; Brommer, Univ. Stuttgart MSc, 2003). The setup phase is
identical (T0 calibration, seed evaluation, stop conditions); only
the per-rung structure differs:
Perturbations are one dim at a time (uniform
U(-1, 1) · V[i]), not whole-vector Gaussians.The per-dim step vector
V[i](initialised fromSTEP_FRAC · (high_i - low_i)) is adapted everyNSstep cycles based on the per-dim accept ratio: it grows when the rate exceeds 0.6 and shrinks when it drops below 0.4.T cools by
RTafter everyNTstep-adjust cycles, so a rung consumesNT · NS · Dhost evaluations (Lis ignored).
Use the Corana variant when the classic variant freezes at low T —
fixed σ proposes broad-search jumps that the cold Metropolis gate
rejects en masse, while V[i] shrinks naturally as the chain
settles into a basin.
PARAM |
Default |
Effect |
|---|---|---|
|
|
Set to |
|
|
Step cycles per step-adjust cycle. |
|
|
Step-adjust cycles per T (cooling triggers every |
|
|
Step-adjust gain — controls how fast |
|
|
Lower clamp on |
|
|
Brommer (2003) modification: snap the chain back to the
best-so-far point after every cooling step. Gives the
adaptive chain “basin memory” — high-T wanders no longer cost
progress because the next rung restarts from the deepest known
basin. Defaults on under |
The per-rung journal line gains a V=[V_min, V_max] field so
users can watch the step vector adapt in real time. The Corana
paper recommends NS = 20, NT = max(100, 5D), but those
values assume cheap function evaluations — a rung costs
NS * NT * D host calls, which is unaffordable for LAMMPS-driven
HPO. The shipped defaults (NS = 5, NT = 5) were picked
empirically at fixed eval budgets on a 42-D EAM workload
(2026-07-13): NT = 5 keeps part of the paper’s
V-equilibration-before-cooling intent and beat NT = 2 by two
orders of magnitude in median best-at-budget; NS = 20 starves
the schedule of rungs and loses despite matching the paper.
Journal output
Per run, ALGO ANNEAL writes the following lines to hpo_run.log
(timestamps elided):
ANNEAL[CLASSIC]: seed=1234 RT=0.85 T_MIN=auto(T0*1e-6) L=20 STEP_FRAC=0.15 REANNEAL=1
ANNEAL: T0=8.188e+00 from 20 probes, median|dE|=1.83e+00 loss range=[3.20e-02, 1.40e+01] std=2.10e+00 target p_accept=8.000e-01 anchor=seed
ANNEAL rung=1/12 T=8.188e+00 proposed=20 accepted=14 (70.0%) oob=2 (9.1%) f_x=2.31e-01 best=1.84e-01
ANNEAL rung=2/12 T=6.960e+00 proposed=20 accepted=11 (55.0%) oob=0 (0.0%) f_x=1.97e-01 best=1.84e-01
...
ANNEAL re-anneal #1: T_start=2.047e+00 from best=8.71e-02
...
ANNEAL summary: rungs=12 proposed=240 accepted=98 (40.8%) oob=4 (1.6%) T0=8.188e+00 T_final=2.46e-01 reanneals=1 best=8.71e-02
ANNEAL accept-rate trajectory: min=20.0% max=70.0%
ANNEAL stopped: MAXEVAL exhausted after 260 host eval(s) (12 rung(s) completed, 1 re-anneal(s))
Use these to diagnose typical SA mistuning:
Accept rate stays at ≈ 100% across all rungs —
T_HOT/T0_PACCEPTtoo high; the chain is doing a random walk. LowerPARAM T0_PACCEPT(e.g. to0.5) or pick a smallerT_HOT.Accept rate collapses in 2–3 rungs —
RTtoo aggressive. UseRT = 0.90or0.95.High ``oob`` fraction (> 30 %) —
STEP_FRAC(orSTEP) too large for the bounds; halve it.Best stagnates while accept rate is > 50 % — chain is escaping basins but not converging; raise
Lto give each temperature more proposals.``ANNEAL stopped: MAXTIME exceeded`` after only a few rungs — the wall-clock cap killed SA before it could cool. Either raise
MAXTIME(in theOPTIMIZERblock or at root level), reduceL, or switch toLIB NLOPT ALGO LN_BOBYQAfor a faster local refinement.
The standard BEST events from HPO_Host (printed by every
optimiser) interleave with the rung lines, so the best-tracking story
is identical to other drivers.
LIB TADAH ALGO ANNEAL_PT — parallel tempering
Parallel tempering (replica exchange) over the same annealing stepper
(classic by default, PARAM CORANA 1 for the adaptive variant).
REPLICAS chains run concurrently at a FIXED geometric temperature
ladder T_COLD .. T_HOT (slot 0 coldest); every SWAP_EVERY
epochs adjacent pairs attempt a Metropolis state swap
(p = min(1, exp((b_i - b_j)(f_i - f_j)))), so better states migrate
cold-ward while hot replicas keep crossing barriers a single cooling
chain gets stuck behind. Swaps move states (x, f), not
temperatures: the Corana step vector V is calibrated to its slot’s
temperature and stays there.
Execution: a persistent worker-thread pool (THREADS) evaluates
replicas concurrently over the one thread-safe host; this ships in
EVERY build (no OpenMP requirement; intra-evaluation OpenMP still
applies underneath — keep THREADS * OMP_NUM_THREADS <= cores).
Same SEED ⇒ identical results for any THREADS (and any MPI rank
count): every replica draws from its own RNG stream, swap coins come
from per-pair streams, and the eval budget is sliced deterministically
per epoch.
Knobs (plus every ANNEAL stepper PARAM):
Knob |
Default |
Effect |
|---|---|---|
|
|
Worker threads evaluating replicas concurrently. |
|
|
Ladder size K (slot 0 coldest). |
|
auto |
Hottest slot; auto-calibrated exactly as ANNEAL’s T0. |
|
|
Coldest slot. |
|
|
|
|
|
Epochs between exchange attempts (an epoch = one rung per replica). |
|
|
Ladder cooling per epoch, |
|
|
0: chain 0 starts at the seed, the rest sigma-jittered around it; 1: chains > 0 drawn uniformly in the box. |
|
|
When 1, snaps ONLY the coldest slot to the global best each epoch (hot replicas exist to explore). |
FTOL_REL/FTOL_ABS arm the Corana sec.-4 plateau on the coldest
slot’s end-of-epoch value + the global best. The journal carries one
line per epoch and a final per-pair swap-acceptance table — tune
LADDER_SPAN/REPLICAS for 20–40% acceptance per pair.
LIB TADAH ALGO ANNEAL_PA — population annealing
Population annealing over the same stepper. POPULATION walkers
anneal together from T_HOT down to T_MIN; each temperature
step (i) reweights every walker by exp(-dbeta * f_i),
(ii) resamples the population (systematic resampling — low-loss
walkers multiply, FAILSCORE walkers die out: the natural cliff
handling), and (iii) runs SWEEPS rungs of the stepper per walker
at the new temperature. Walker state (x, f, V) is copied on
resample — children inherit the parent’s step calibration — while
each SLOT keeps its own RNG stream, so results are identical for any
THREADS / rank count.
Knob |
Default |
Effect |
|---|---|---|
|
|
Worker threads evaluating walkers concurrently. |
|
|
Population size R. |
|
|
Rungs per walker per temperature step. |
|
|
Adaptive schedule: pick the largest |
|
|
As in ANNEAL_PT. |
|
auto / auto / |
As in ANNEAL. |
Per-step journal line: T, ESS, unique parents, culled count,
finite fraction, population best. FTOL_REL/FTOL_ABS arm the
plateau on the population best.
Multi-node runs (TADAH_HPO_MPI) and ARCHER2
Both parallel drivers scale past one node through the opt-in
-DTADAH_HPO_MPI=ON CMake option: replicas/walkers distribute over
MPI ranks in contiguous slot blocks, every rank trains locally and
runs its LAMMPS instances on MPI_COMM_SELF, and only tiny control
messages travel (swap decisions, resampling plans, best-broadcasts).
The SAME config file runs serially, threaded, or under srun /
mpirun unchanged; REPLICAS/POPULATION are global counts.
Requirements and behaviour:
an MPI-flavoured LAMMPS library (the serial archive carries MPI stub symbols that collide with a real MPI at link time — configure-time check);
MPI_THREAD_MULTIPLE(evaluation threads run LAMMPS concurrently); on Cray MPICH:export MPICH_MAX_THREAD_SAFETY=multiple;fixed-name outputs gain a
.r<rank>suffix on ranks > 0; rank 0 re-evaluates the global best once at the end so ITSbest_*.tadahfiles always carry the global winner;MAXEVALis enforced globally (allreduced accounting);mutually exclusive with the legacy
TADAH_BUILD_MPI(ScaLAPACK-distributed training) build.
ARCHER2 sketch (128 cores/node, 2x AMD EPYC 7742; inter-node communication requires MPI; OpenMP cannot span nodes):
#!/bin/bash
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=8 # MPI ranks (replica blocks)
#SBATCH --cpus-per-task=16 # eval threads per rank
#SBATCH --time=01:00:00
export OMP_NUM_THREADS=4 # intra-eval LAMMPS fan-out
export MPICH_MAX_THREAD_SAFETY=multiple
# THREADS 4 in the STRATEGY block: 4 workers x OMP 4 = 16 cores/rank
srun --distribution=block:block --hint=nomultithread \
tadah hpo --hpotarget config.hpo -c config.train
Size the run as ranks * THREADS * OMP_NUM_THREADS <= total cores,
with REPLICAS (PT) a multiple of the rank count and roughly
THREADS replicas per rank.
RESTART decorator
RESTART { ... } ENDRESTART decorates a TYPE PLAIN /
MULTISTART / PRESTAGE strategy with a stagnation watchdog.
STRATEGY
TYPE PLAIN
LIB DLIB
ALGO BFGS
MAXEVAL 1000
RESTART
AFTER_STAGNATION 80
MAX 5
STRATEGY SOBOL 1
ENDRESTART
ENDSTRATEGY
Key |
Args / range |
Effect |
|---|---|---|
|
int ≥ 0 |
After this many consecutive evals without a new global-best,
abort the inner run and restart from a fresh seed. |
|
int ≥ 0 |
Cap on restart count. |
|
repeatable |
Init chain used to draw the fresh point on each restart
(re-uses the |
Each restart gets its own stagnation window — the windows do not bleed into each other.
NOISE block
NOISE { ... } ENDNOISE controls how HPO handles objective noise.
NOISE
AUTO
CALIBRATION 0
ENDNOISE
Key |
Args |
Effect |
|---|---|---|
|
bool |
Auto-derive the finite-difference step |
|
int (0 or ≥2) |
Repeat the seed evaluation |
INNER block — NLopt MLSL / AUGLAG sub-optimiser
NLopt’s MLSL / G_MLSL_LDS / AUGLAG drivers delegate inner work to a local optimiser. Configure the inner via:
STRATEGY
TYPE PLAIN
LIB NLOPT
ALGO G_MLSL_LDS
MAXEVAL 400
INNER
LIB NLOPT
ALGO LN_BOBYQA
MAXEVAL 50
ENDINNER
ENDSTRATEGY
Only the driver-attribute keys (LIB / ALGO / MAXEVAL /
FTOL_* / STEP / SEED / PARAM / POPULATION /
THREADS / VECTOR_ARR) are valid inside INNER.
Load-time data transforms
The training-side load transforms (LSCALE, ESHIFT*,
EFILTER / FFILTER, EWEIGHT_TEMP, WDBFILE /
WDBFILE_AUTO, ZERO_COM_FORCE) are documented under
Load-time data transforms; place them in --config (the training
configuration). HPO applies them on every inner training run.
Validation-set sanitisation
The validation set is transformed with a stripped context that contains:
LSCALEfrom the training (master) configuration,the resolved
ESHIFTfrom the training run (soESHIFT_ATOM/ESHIFT_DBATOMderivations propagate as per-Z values; the raw*_ATOM/*_DBATOMkeys are not re-derived on validation),EFILTERandFFILTERonly when they appear in the –validation file itself.
Training-only knobs — EFILTER / FFILTER set in the master
config, WDBFILE / WDBFILE_AUTO, EWEIGHT_TEMP,
ZERO_COM_FORCE — never reach the validation set: they would
silently change what the validation metric is computed on without
the user opting in, breaking apples-to-apples comparison across HPO
trials.
Per-validation outlier removal is therefore declared in the file you
pass to --validation directly:
# validation.in
DBFILE val_eos.tadahdb
EFILTER -12.0 -2.0 # honoured for validation only
FFILTER 20.0
The host emits a single INFO log line at start-up summarising
the resulting validation set:
Validation set: 532 configs loaded; dropped 4 by EFILTER, 1 by FFILTER; 527 remain.
The line is unconditional — when no filter is active the dropped counts are zero and the line still confirms the loaded size, so it is always clear which configs the validation metric is being computed on.
Output files
Unless you change them, every artefact produced by the outer optimiser
is written to the directory in which you started tadah hpo.
Main log files
Each file begins with a header line that starts with # and
describes the columns. One line per iteration. The first column is
always the step number.
File |
Columns |
|---|---|
|
Wall-time, all individual loss terms, then the total loss. |
|
The current hyperparameter vector in the order defined by |
|
Additional variables requested with |
Cadence and formatting:
Key |
Default |
Effect |
|---|---|---|
|
|
Write a new line every |
|
|
Decimal digits in scientific-notation columns; |
|
|
Number of rows buffered before the writer thread flushes to disk. |
Best-only snapshots
Whenever a new minimum of the global loss is found the corresponding rows are copied to companion files:
best_loss.tadahbest_params.tadahbest_outvar.tadah
Each contains a single line — the best result so far — useful for monitoring progress without parsing the full history.
Key |
Default |
Effect |
|---|---|---|
|
|
Write to the |
Potential archives
The current best potential is always saved to best_pot.tadah.
Key |
Default |
Effect |
|---|---|---|
|
|
Save every trial potential every |
|
|
As |
Run log
hpo_run.log records a single structured snapshot of the resolved
configuration at run start, including:
Init strategy:block — the resolved init chain.Run policy:block — the active run policy.LOAD TRANSFORMSsection — every applied load-time transform plus the equilibrium-volume diagnostic.
Either hpo_run.log or the stdout markers in
Diagnostic stdout markers is the canonical record of which features
fired during a run.
Practical tips
Large optimisations can produce thousands of potentials; watch disk usage when
DUMPis enabled.The log files are plain text and append-only. They tail-friendly:
tail -f loss.tadah
Each row in
params.tadahmatches the order ofOPTIMdirectives exactly, so a row may be replayed verbatim withtadah train.
Warm-start protocol and bad-potential early-exit
Warm-start: ${hot_a0} (or any --hotvar)
For LAMMPS scripts that start with a box/relax from a hard-coded
lattice guess (typical for elastic constants, surface energies, …), HPO
can short-circuit the expensive minimisation:
Declare the producing
PC_LAMMPSline as hot:PC_LAMMPS --script in.a0_relax \ --hotvar hot_a0 2.5 4.5 3.302 \ --varloss ...<min> <max>bound the physical range;<initial>is optional (midpoint of[min, max]when omitted).Replace the hard-coded
lattice bcc 3.2in that script withlattice bcc ${hot_a0}.End the script with a
string-style readback (notequal):variable hot_a0 string $(lx/<divisor>)
where
<divisor>matches the conventional cell size (e.g.4.0for a 4-atom BCC conventional cell). Equal-style readback does not currently round-trip across iterations inside the cached LAMMPS instance — use string-style until that is lifted.
HPO injects ${hot_a0} as a string-style variable on every call
(<initial> from --hotvar on the first call, the cached value
thereafter), captures the script’s ${hot_a0} after each successful
run, and reuses it on the next evaluation. The variable is then
propagated as ${hot_a0} into every cold (no---hotvar)
PC_LAMMPS script in phase B. When WARM reads a pot.tadah
whose writer dumped # HOT_A0 <script> <a0> lines, the cache is
primed automatically; [HPO] WARM: primed warmstart cache with N
HOT_A0 entry(ies) confirms how many lines were absorbed.
Multiple --hotvar flags may be repeated on the same PC_LAMMPS
line; hot_a0 is just a conventional name (any identifier works).
Per-line legacy environment variables (TADAH_HPO_HOT_A0_DEFAULT,
TADAH_HPO_A0_MIN, TADAH_HPO_A0_MAX) were removed in this
release; the per-line --hotvar flag replaces all three.
Bad-potential early-exit
Two cheap checks let HPO skip the expensive LAMMPS stage when training has produced an unphysical potential:
the per-metric
PC_<METRIC> --skip-above/--skip-relfilters documented at PC_* — performance constraints (Per-metric bad-pot pre-filter), andthe post-LAMMPS
--hotvarrange filter described above (a relaxed value outside[min, max]fail-scores the iteration and does not update the cache).
The legacy TADAH_HPO_BAD_POT_ERMSE_MEV / _REL environment
variables were removed in this release; use
PC_ERMSE … --skip-above <cap> / --skip-rel <ratio> instead.
Performance & parallelism
Tadah!MLIP comes in two flavours; the parallel strategy you can exploit depends on which one you compiled.
Desktop build (OpenMP)
Inner loop — regression and descriptor evaluation are OpenMP parallel. Set the number of threads in the usual way:
export OMP_NUM_THREADS=<n>
Within a single iteration HPO drives
min(N, n_scripts)PC_LAMMPSinstances concurrently — one per OpenMP thread, each on its own freshly-constructedLAMMPS_NS::LAMMPSinstance.Outer loop —
DLIB:GFSevaluates several hyperparameter sets concurrently whenTHREADS Kis set in theSTRATEGYblock. Other optimisers ignoreTHREADS.Rule of thumb:
THREADS × OMP_NUM_THREADS ≤ number of physical cores
Exceeding this limit will not crash the run, but the OS will oversubscribe cores and overall performance will drop.
LAMMPS runs — Tadah!MLIP always links a serial LAMMPS library; parallelism is driven around LAMMPS, not inside it.
MPI build
The MPI variant parallelises the inner regression across all ranks (host–client pattern). It must be linked against the MPI version of LAMMPS. Each LAMMPS calculation is spawned independently from the main communicator:
--ncpu <m>On a
PC_LAMMPSline, requests that m ranks form a mini-MPI world and execute the script. SeveralPC_LAMMPSlines may run side by side, each with its own--ncpuvalue. The sum of all requested ranks must not exceed available ranks − 1 (one rank is reserved for the host).
Note
The MPI launcher is functional but still experimental; improved error handling and dynamic load balancing are in development.
Example:
srun -n 64 tadah hpo … # 64 MPI ranks available
...
PC_LAMMPS --script in.elastic --ncpu 8 …
# spawns mpirun -n 8 lammps …
Practical advice
For inexpensive models you usually gain more by increasing
THREADSthan by adding OpenMP threads — context-switch overhead is lower.For very large training sets the regression dominates; in that case set
THREADS = 1and devote the cores to OpenMP (desktop build) or MPI.Measure, do not guess: a few short test runs sweeping
OMP_NUM_THREADSandTHREADSover {1, 2, 4, …} will quickly reveal the sweet spot on your machine.
Diagnostic stdout markers
HPO emits a one-line stdout (or stderr) marker each time a notable event fires. They are stable and intended to be grep-friendly.
Marker |
Meaning |
|---|---|
|
Active driver and search-space dimension. |
|
After init resolution. |
|
|
|
|
|
Warm point fell outside narrowed bounds. |
|
Multi-seed forwarding. |
|
MULTISTART fires. |
|
Either from |
|
Per-start. |
|
PRESTAGE phase starts. |
|
Snapshot quality after PRESTAGE finishes. |
|
Outer (refinement) phase starts. |
|
Stagnation watchdog fired. |
|
|
|
|
See also
Nested Fitting — Worked Examples — fifteen worked examples covering the optimiser libraries and the
INIT/STRATEGY/EXPLORE/RESTART/INNERblocks.Example 2 - Basics: Nested Fitting Procedure — minimal single-loss-term walkthrough.
HPO/README.md — full keyword reference, defaults, and the OPTIM-able context keys reinit-safety table.